Niegdyś musiałem stworzyć zbiór Enumów i umieścić go w polu static final. Pełen optymizmu skorzystałem z Set.of() z JDK9. Zdziwiłem się jednak, gdy SonarQube zgłosił, że jeśli używam zbiór Enumów, to powinienem użyć EnumSet. Wewnętrzne wzburzenie nie dawało mi spokoju, bo przecież Set.of() jest niemutowalne i korzysta ze @Stable wewnątrz, więc lepsze powinno być preferowane w tym względzie…
Po ponad 1,5 roku postanowiłem zweryfikować, co o moim przekonaniu mówią benchmarki.
EnumSet
Najpierw warto zajrzeć w szczegóły implementacji klasy EnumSet.
Zacznijmy od tego, że jest to klasa mutowalna, której wartości muszą dziedziczyć po klasie Enum.
Każda wartość wyliczeniowy posiada przyporządkowaną wartość ordinal(), która jest intem. Zatem zbiór Enumów może być reprezentowany poprzez pojedyncza liczbę, której poszczególne bity będą zapalone, gdy dany Enum (z odpowiednim ordinal()) będzie w zbiorze.
Zatem, aby przechować Enum o max 64 wartościach, wystarczy liczba typowana longiem. Jednak jak przechowywać Enumy o większej dziedzinie? Wówczas zamiast jednej liczby można użyć tablicy liczb.
Powyższe stwierdzenia przekładają się na implementację – EnumSet jest tak na prawdę klasa abstrakcyjną (udostępniającą metody fabryczne) i posiada dwie podklasy – RegularEnumSet reprezentujący jednym longiem dla Enumów o max 64 wartościach oraz JumboEnumSet ze stanem trzymanym w tablicy longów.
Set.of()
Set.of() zwraca zawsze klasę niemutowalną. Jeśliby zajrzeć w implementację metody Set.of(), to można zobaczyć, że zwracana klasa zależy od liczby elementów. Dla pustej listy zwracana jest instancja SetN, dla jednego i dwóch elementów – Set12, a dla trzech elementów wzwyż – ponownie SetN.
Set12 jest implementacją obsługująca wyłącznie jednoelementowe i dwuelementowe zbiory. Wewnątrz klasy są zawarte dwa pola, w których umieszczany jest pierwszy i opcjonalnie drugi element. Dzięki temu, że korzystamy z pól, a nie z tablicy oszczędzamy jeden odczyt z pamięci. Dodatkowo implementację metod w przypadku max dwóch elementów są trywialne – nie trzeba nawet iterować po tablicy (wszak jej nie ma ;)).
Implementację zwracane przez Set.of() są niezmienne, zatem można pokusić się o optymalizację odczytów. Takie pole, które na pewno jest niezmienne można oprócz oznaczenia finalem (a które niewiele daje), można oznaczyć adnotacją @Stable. Ta adnotacją dostępna dla modułów JDK upewnia kompilator, że wartość oznaczona NA PEWNO nie zostanie zmieniona. Użycie tej adnotacji jest wykorzystywane co najmniej w przypadku pól static final.
Zarówno na polach z elementami (dla Set12), jak i tablicy z elementami (SetN) jest użyte @Stable.
Zajętość pamięci
Pierwszym aspektem jest zmierzenie ile pojedynczy zbiór Enumów zajmuje pamięci. Zmierzone zostały zarówno same obiekty zbioru, jak i tworzone przez nie obiekty. Nie zostały jednak wzięte pod uwagę obiekty współdzielone między wiele instancji (np.EnumSet.universe lub dane klasy czy refleksji).
Wielkości są badane dla zbioru pełnego danych Enumów t.j. zbiór Enumów o N wartościach zawierający wszystkie możliwe wartości tego Enuma.
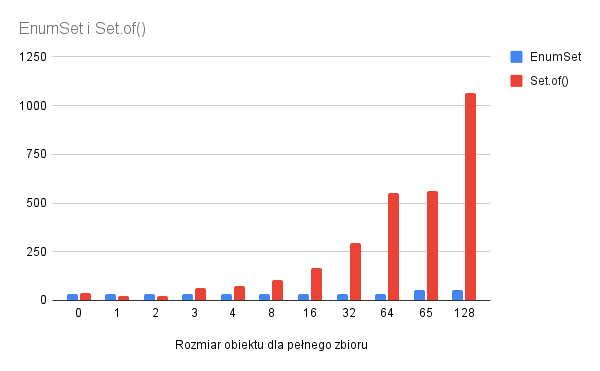
Otóż o ile dla jednego i dwóch elementów mniej waży Set.of(), o tyle w pozostałych przypadku lepiej wypada EnumSet, który rośnie tylko o 8 bajtów na każde 64 elementów dziedziny. W przypadku Set.of() każdy dodatkowy element w zbiorze zajmuje 8 bajtów.
Benchmark
Z braku czasu nieco poszedłem na skróty i badałem jednocześnie zarówno wpływ wielkości domeny (liczba dostępnych wartości danego Enuma), jak i wielkość zbioru.
Wielkość domeny powinna zmniejszać wydajność EnumSeta co każde 64 dostępnych wartości, niezależnie od zawartości zbioru.
Z drugiej strony wielkość zbioru powinna zmniejszać bardzo szybko wydajność Set.of() oraz znacznie wolniej wydajność EnumSeta.
Set.contains()
W tym przypadku badany był przypadek, gdzie sprawdzana była obecność ostatniego elementu domeny Enuma. Wielkość zbioru jest równocześnie wielkością dziedziny. Weryfikowane były dwa warianty – gdy trzymamy taki zbiór w polu statycznym finalnym (s.f.) i po prostu w finalnym.
Wyniki przedstawiane są poniżej (liczba operacji na sekundę – im więcej tym lepiej ;))
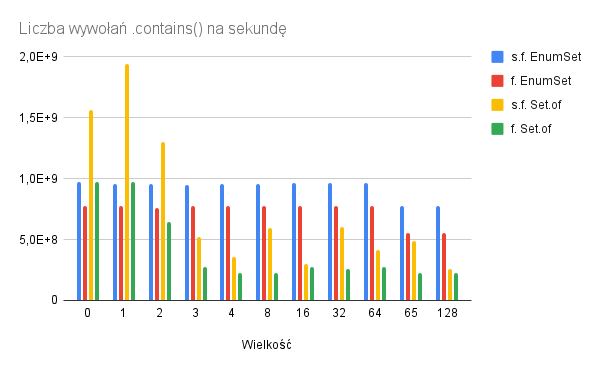
W przypadku pola static final operacja .contains() działa szybciej dla Set.of() zawierający 0, 1 lub 2 elementy (o 10%-50%). W pozostałych przypadkach EnumSet działa szybciej.
Co ciekawe, acz logiczne dla EnumSet dla dziedziny do 64 Enumów działa tak samo szybko niezależnie od zawartości zbioru (operacje na bitach są… szybkie ;)).
Zastanawiającą rzeczą do dalszego rozważania we własnym zakresie zostawiam „losowość” wydajności Set.of() dla większych niż 2. Dla pól static final wydajność „skacze”.
W przypadku pól finalnych przewaga Set.of() jest widoczna tylko dla pustego i jednoelementowego zbioru. Dla większych zbiorów EnumSet wygrywa.
Porównywalna byłaby wydajność dla 2 elementowego zbioru o dziedzinie większej niż 64 elementy, zatem zawsze przy wyborze EnumSet vs Set.of() należy brać pod uwagę dwa czynniki – dziedzinę i wielkość zbioru.
Set.containsAll()
W drugim badanym benchmarku brałem pod uwagę operacje .containsAll() w argumencie podając zbiór pełny. Tutaj również brałem pod uwagę dwa przypadki: gdy argumentem jest zbiór tego samego typu i gdy zbiór jest innego typu.
Wyniki przedstawiane są poniżej (liczba operacji na sekundę – im więcej tym lepiej ;))
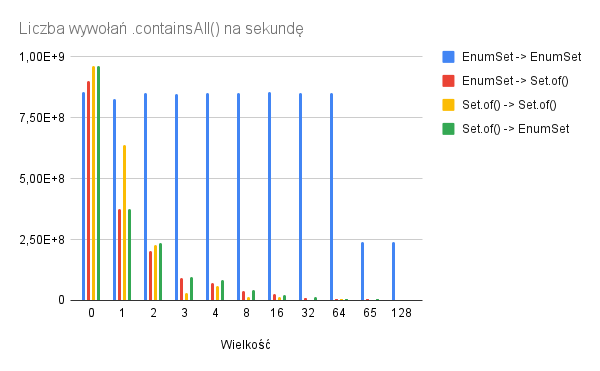
W przypadku .containsAll() użycie Set.of() jest uzasadnione w zasadzie tylko w przypadku pustego zbioru. Wyniki również jasno pokazują, że w przypadku korzystania z EnumSeta, warto zadbać o to, by argumentem .containsAll() był również był EnumSet – wówczas dla dowolnej zawartości zbioru wydajność jest taka sama i zależyna wyłącznie od dziedziny.
Podsumowanie
Mając do dyspozycji Set.of() i EnumSet wybór należy uzależnić od dziedziny Enuma oraz wielkości zbioru. Dla 0,1,2 elementów lepiej wypada Set.of(), szczególnie, gdy dziedzina ma więcej niż 64 elementy. W pozostałych przypadkach lepiej wybrać EnumSeta.
Zasadniczo, mając do dyspozycji jedno i drugie, to warto rozważyć trzecie 😉 Jest kilka bibliotek, które implementują interfejsów standardowych Javowych kolekcji – chociażby Eclipse Collections, Apache Commons Collections lub choćby stara dobra Guava. Z ciekawostek to istnieje implementacja Mapy trzymająca elementy poza heapem – Chronicle Map.
Wszelkie źródła, benchmarki itd pod tym adresem.
Jednak ten SonarQube miał rację… 😉
Pax et bonum!
P. S. Ten tekst powstał w połowie w komunikacji miejskiej i pociągu. Dziękuję MPK i PKP 😉
 Asdf movie
Asdf movie