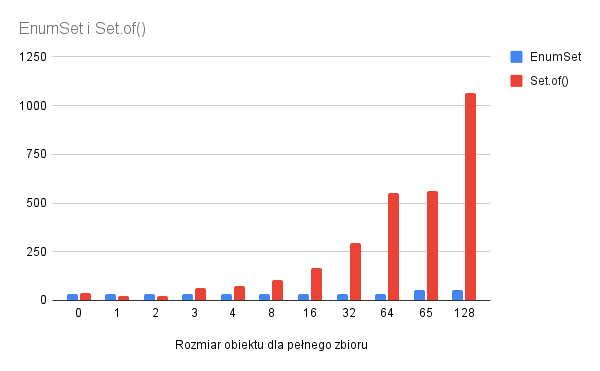
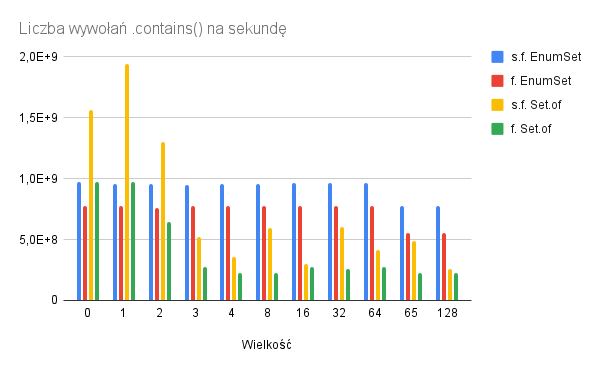
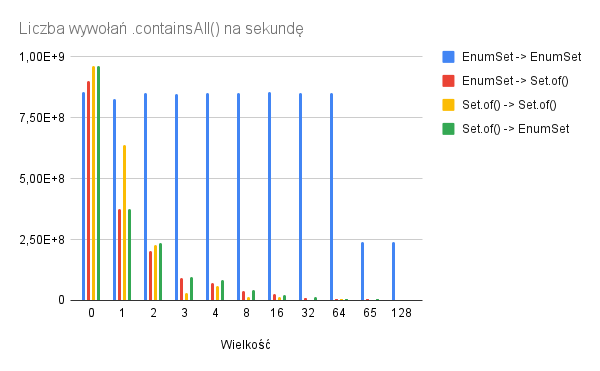
Po 4 wpisach o subiektywnie wybranych aspektach i subiektywnych odczuciach względem nich, czas na podsumowanie. Wiele wody w Warcie upłynęło od pierwszego wpisu o Quarkusie, ale to dobrze – przez grubo ponad rok trochę się zmieniło również w sytuacji Quarkusa.
Perspektywa developerska
Nie bez powodu jedną z zalet, którą się Quarkus chwali jest Developer Joy. Tryb developerski będący integralną częścią, a nie tylko dodatkiem, sporo przyspiesza. Przeładowanie kontekstu bez ubijania aplikacji i potrzebnych kontenerów, bez ponownego ładowania bibliotek i wizualna konsola developerska to rzeczy, które naprawdę się przyspieszają development.
Chyba, że mówimy o aplikacjach natywnych budowanych z użyciem GraalVM Native Image – wtedy cóż… development jest powolny sam z siebie, gdyż kompilacja do natywki trwa… Ze strony Quarkusa jest dodatkowe wparcie dla GraalVM Native Image takie jak customowe adnotacje, lifecycle wspierające zbieranie metadanych, czy testujące aplikację natywną. Nie ma jednak już takiego efektu wow, jaki był w czasach, gdy Spring Boot nie wspierał kompilacji natywnych.
Bardzo przydatną rzeczą jest tzw. DevUi w trybie deweloperskim. Pozwala ona nie tylko na podejrzenie co w uruchomionej aplikacji siedzi (jakie ostatecznie propsy są ustawione, podejrzenie JWT, a nawet querowania SQLek używając aplikacyjnego użytkownika i podglądanie kolejek), ale też na uruchomienie testów, wywoływanie endpointów przez Swaggera, czy GraphQLowych komend.
Idealnie by było, gdyby wiązałoby się to z kolejnym featurem – Remote Dev Mode, jednak niestety aktualnie obie rzeczy jednocześnie nie są wspierane… A Remote Dev Mode pozwala na łatwą podmianę kodu w zdalnej instancji (po wyłączeniu kilku bezpieczników). Ma to swoje wady takie jak nieprawomyślność z security, czy z 10 postulatem z Twelve-Factors, ale możliwość przetestowania zmiany, czy fixa NPE w sekundy, a nie w minuty jest nieoceniona.
Perspektywa biznesowa
Nie jestem biznesmenem, więc moje zdanie może być spaczone. Jednak same przytoczone poniżej argumenty nie zależą od mojego zdania 😉
Quarkus jest aktualnie pod opieką Commonhaus, który odpowiada też za Jacksona, Hibernate’a, Sdkmana, Debezium i inne. Projekt wspierany jest głównie przez RedHata albo też IBMa, wszak to jest/będzie jedność. Początki miał w 2018, wersja 1.0.0 wypuszczona w 2019 zatem jest już całkiem stabilnie.
Jest wiele projektów, które działają na Quarkusie. Niektóre historie zostały opisane na blogu Quarkusa (Orange, Vodaphone). Na Quarkusie bazuje Keycloak. Istnieje strona TheirStack, na której można sprawdzić, jakie technologie są używane w różnych firmach, ale bazuje ona na prasowaniu treści ofert pracy, więc nie oceniam wiarygodności 😉
O ile jeszcze półtora roku temu znalezienie pracy z wymaganiem Quarkusa na Polskim rynku pracy graniczyło z cudem, to o tyle teraz regularnie na różnych portalach jest po kilka ogłoszeń. Można to czytać, że już trochę projektów w Quarkusie powstało i ich nie zaorano – szukają na naszym polskim grajdołku ludzi, którzy będą utrzymywać i rozwijać to, co już jest. Zatem Quarkus przetrwał pewną próbę czasu. Nie jest to jednak stabilność i dojrzałość Springa.
Warto jednak wspomnieć, że Quarkus bazuje na znanych i dojrzałych standardach związanych z Jakarta EE takich jak Microprofile. Dlatego też migracja z Jbossa lub Wildfly nie powinna być udręką. Adam Bien, Java Champion pracujący głównie na Jakarta EE w podkaście Quarkusowy jest wręcz Quarkusem zachwycony.
Jeśli chodzi wsparcie, istnieje płatne wsparcie od RedHata. Za darmo to mamy wersję Long Term Support wydawane co pół roku i minorowe wersję wydawane co miesiąc. Bugi się zdarzają i w razie potencjalnego buga najłatwiej szukać pomocy na Github Issues – jeśli to rzeczywiście bug, to prawdopodobnie jest spisany.
Jeśli coś bardzo niszowego nas uwiera, a jest z perspektywy community mało krytyczne, można samemu kontrybuować i jest to mile widziane. Sam ze 3 minorowe kontrybucję poczyniłem i community dość aktywnie wspomagało w kontrybucji.
A jak to się ma do Spring Boota?
Nie ma co ukrywać, że to Spring Boot jest standardem rynkowym, zatem opisując framework nie sposób ich nie porównać.
W czym Quarkus jest lepszy?
- Prędkość developmentu
dev mode, faster startup, krótsza feedback loopa – that’s why. - Dokumentacja jest spójna i aktualna
Spring ma wiele źródeł nauki, każde z inną wersją + odpowiedzi na stackoverflow z 2010 roku – czasem ciężko to odsiać googlem.
W Quarkusie dokumentacja jeszcze nie zdążyła się zdezaktualizować. - Faster startup, lower footprint, optymalizacje w build-time, brak skanowania adnotacji w runtime
Technologicznie Quarkus jest to bardziej nowoczesny, nie ma tam 20 letniego kodu i podejść z poprzedniej epoki. - Możliwość kontrybucji
Nie próbowałem kontrybuować do Spring Boota, ale nie aby to było proste (tak – to subiektywne podejrzenie; być może mylne…).
Można też podważyć to, czy jest to w ogóle zaleta 😉
W czym Spring Boot przeważa?
- Dojrzałość technologiczna i masa integracji z innymi technologiami
Nie wiem, czy w Spring Boocie są jeszcze jakieś bugi – ja takowych nie spotkałem… W Quarkusie wiem, że są (choć łatane na bieżąco) 😉 - Powszechny standard i domyślny framework dla Javy
Prawdopodobnie każdy Javowiec kiedyś pracował ze Spring Bootem. Zatem zrekrutować programistę znającego Spring Boota jest proste. - Projekty powiązane
Do niedawna Spring Data istniał tylko w Springu; dopiero niedawno pojawiła się Jakarta Data, która jakoś adresuje ten brak.
Cóż więcej?
Podejrzewam, że to inne frameworki wspierając GraalVM Native Image były główną motywacją do wsparcia tejże technologii przez Spring Boota. Podobnie devservice’y mogły zainspirować integrację z docker-compose.
Zatem zasadniczo dobrze, że Spring Boot ma konkurencję – poprzez wzajemne inspiracje frameworki tylko zyskują na jakości.
Podsumowanie podsumowania
Wygląda na to, że Quarkus wypracował sobie pewną stabilną pozycję na rynku. Najbardziej dynamiczny rozwój już pewnie minął, ale to dobrze – wypracowywana dojrzałość tego frameworka jest oczekiwana.
Z pewnością nie jest to domyślny framework dla Javy – tu monopolistą przez lata zostanie Spring (o ile Broadcom nie postanowi jakoś go agresywnie zmonetyzować). Jednak tam, gdzie wydajność, oszczędność zasobów i startup time na znaczenie, jest to warta rozważenia alternatywa. Przy czym aktualnie do pracy z Quarkusem raczej potrzeba ogarniętego Seniora, niż Juniora, stąd pewnie więcej pieniędzy zainwestować w budowaną aplikację.
Linki
Poprzednie wpisy:
- Quarkus – luźne przemyślenia po 500h developmentu (cz. 1)
- Quarkus – luźne przemyślenia po 500h developmentu (cz. 2 – GraalVM – Javascript i Native Image)
- Quarkus – luźne przemyślenia po 500h developmentu (cz. 3 – praca z kodem)
- Quarkus – luźne przemyślenia po >500h developmentu (cz. 4 – rozmaitości)
Pax et Bonum!